
The Summer of Japanese Puppets, Part 2
12 July 2017
This post is part 2 of 4 in a series. Feel free to skip around to:
part 1: the task, part 3: the site, or part 4: epilogue.
Act 2: Data transformation montage
After taking a detour prototyping with Google Lovefield + IndexedDB and making a pitstop to play with GraphQL, I finally settled on a simpler plan: export each object type as an array of JSON records, and have each record point to its relationships via arrays of IDs. With this thought, the montage began:
scene i. plan + tidy
In: MySQL dump
Tools: any ol’ erd / OpenRefine / json-schema
I started by using a simple entity relationship diagramming (ERD) tool and JSON Schema to plan out what each object type (e.g. play, kashira, character, etc.) should look like at the end of the processing stage by asking/answerinq questions like: Which keys does each type need? Which keys should be named in a standardized way across object types? What kind of value does a given key expect (maybe an int? a nullable string…? ), and does it expect 1 or many? What does the object need to “know” about itself, and what can it inherit from other types?

{
"$schema": "",
"definitions": {},
"id": "author",
"properties": {
"authors": {
"items": {
"properties": {
"id": { "type": "integer" },
"label_eng": { "type": "string" },
"label_ka": { "type": "string" },
"dates": { "type": "string" },
"reference": { "type": "string" },
"sort_ja": { "type": "string" },
"play_id": {
"items": {
"properties": {
"id": { "type": "integer" }
},
"type": "object"
},
"type": "array"
}
}
}
}
}
}
Once each type was reasonably mapped out, I exported the MySQL database as a set of CSV files and turned to OpenRefine to clean them up. I used faceting to get a better sense of each set, recast strings as ints and visa versa, scrubbed out line breaks, dropped unused columns, consolidated similar cells, and so on. Then I renamed as many columns as possible to cohere to the somewhat-standardized JSON schema I’d created, and re-exported them as spiffed-up CSVs.
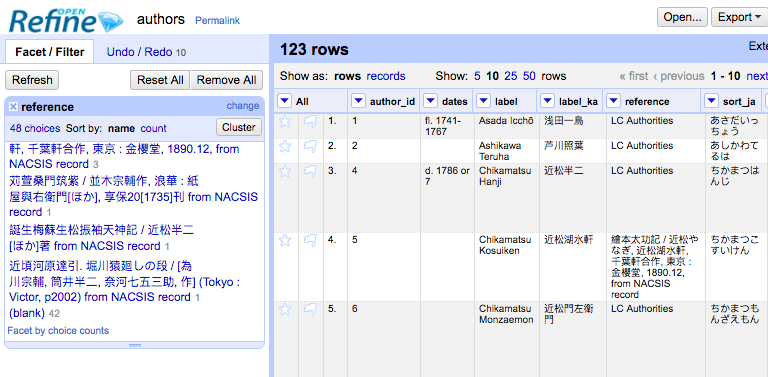
Out: Optimized CSVs
scene ii. Process + convert to JSON
In: CSVs
Next I created an iPython (aka Jupyter) notebook imported Pandas, which is a data analysis library built on Numpy. Pandas works primarily with a datatype called a dataframe, which takes its name from the same type in R.
After reading each CSV file into my Jupyter notebook as a Pandas dataframe, I was able to perform powerful SQL-like tasks on the data, including a chained .merge() .groupby() .apply(list) function that allowed me to merge a join table onto a dataframe, appending an array of ids from the join onto each row.
For example, given a dataframe of authors and a join table of author_ids and play_ids, the function (shown below) will merge a list of play_ids on to each corresponding author record. This is exactly the task I needed to perform on most data objects—adding multiple plays to each author, multiple performances to each play, multiple scenes to each performance, and so on.
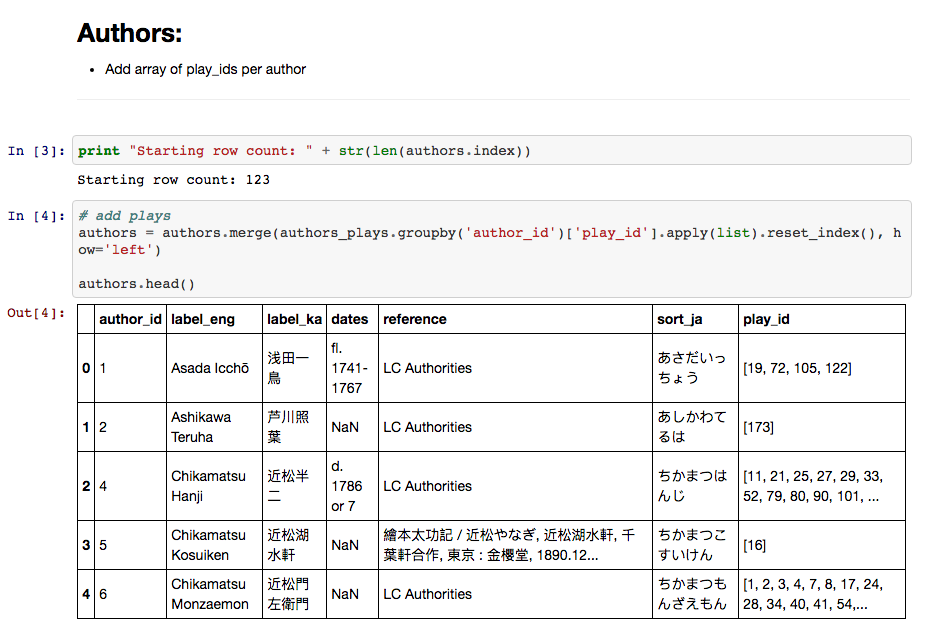
Once each dataframe was transformed to mirror the JSON schema I’d planned, I wrote them out to new json files using Pandas’ .to_json(orient='records') function. (You can see the complete process and notebook here.)
An aside: If i were more versed in the powers of Jupyter and Pandas at the time, I could have connected my notebook directly to the MySQL database and performed the cleaning tasks of OpenRefine with Pandas, skipping the CSV steps entirely. For tips on something similar, check out this post.
Out: JSON
scene iii. Minify
In: JSON
Tools: JQ
With the bulk of the processing done, I used a few post-processing tricks to make my JSON files smaller and more usable. I used the JSON manipulation library JQ to drop null key:value pairs from my files, since most objects (especially images) had a lot of empty fields. I also used the option --compact-output to minify the non-null files:
$ jq 'del(.[][] | nulls)' --compact-output authors.json > authors-min.json
Bonus: if you have MySQL installed on your machine, you can use the string REPLACE function to swap out any null arrays ([null]) or null values that stayed defined as Pandas’ NaN for a true null before using JQ, and make sure that it drops *every* null pair possible. If not, you can also use grep and sed, though it’s less straightforward.
$ replace "[null]" "null" -- authors.json
$ replace "\"nan\"" "null" -- authors.json
Out: better JSON