
The Summer of Japanese Puppets, Part 4
14 July 2017
This post is part 4 of 4 in a series. Feel free to skip around to:
part 1: the task, part 2: data transformation, or part 3: the site.
epilogue
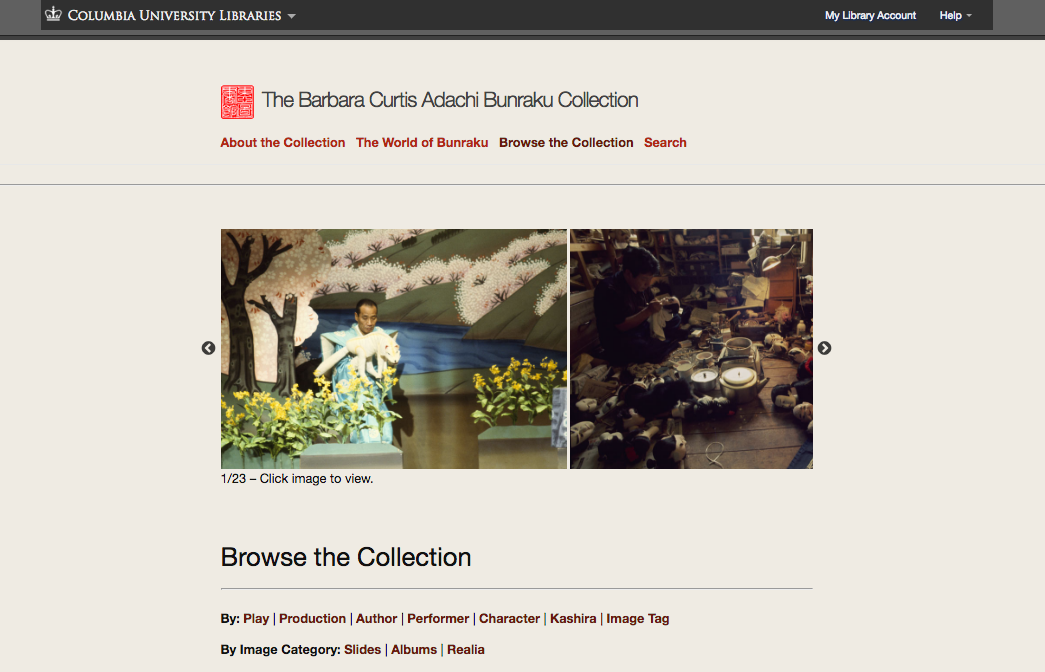
The demo!
The mostly finished demo has directories of plays, productions, performances, authors, performers, characters, kashira, scenes, and image tags
with individual layouts displaying and linking object data together.
It is navigable through the above directory listings, through several dynamic search boxes running client-side Lunrjs, and via clickable D3js data visualizations. It handles relative/massive image sets by implementing lazy load in a jQuery carousel.
tl;dr.
- Started with a Cake PHP site powered by a relational MYSQL database.
- MySQL dump to CSVs.
- Imported CSVs into IPython as Pandas dataframes.
- Merged relational data (from CSV jointables) onto dataframes by type.
- Exported dataframes as JSON records (and CSVs, for archival purposes only).
- Dropped null key:value pairs from JSON using JQ.
- Generated Jekyll collections (and pages) from YAML using wax_tasks gem.
- Ended with a ~40k page static Jekyll site powered by YAML data, with JSON index for client-side search.